Linux コマンドラインのコンセプト: cut コマンド
この記事は、シリーズ 機械学習エンジニアのためのLinux の第7回です。
前回の復習
前回の記事では、「データセット内のファイル一覧をCSV形式で出力する」という問題を考えた。
その際に、パイプ機能と tr コマンドを利用して、ファイルパスをCSVフォーマットに変換した。
しかし、出力の先頭に余分な文字(.,)が付いてしまっていた。
今回は、この余分な文字を取り除くのに役立つ cut コマンドを学び、問題の解答となるコマンドを作成しよう。
cut コマンド
cut コマンドは、入力したテキストのそれぞれの行から一部だけを抽出するコマンドだ。
抽出のしかたには、「文字の位置を指定する方法」と「列を指定する方法」の2通りがある。
文字の位置を指定して抽出する
cut に -c オプションを渡すと、文字の位置を指定して抽出することができる。
find . -type f というコマンドの出力を cut でフィルタする場合を例として考えよう。
find コマンド単体の出力は次のとおりだ。
$ find . -type f
./README.txt
./train/speaker_a/speech_0001.wav
./train/speaker_b/speech_0002.wav
./validation/speaker_a/speech_1001.wav
./validation/speaker_b/speech_1002.wav
cut -c 3 をパイプでつなげると、出力の各行から3文字目だけを取得できる。
$ find . -type f | cut -c 3
R
t
t
v
v
ハイフン(-)を使うと、複数の文字を範囲指定することもできる。
例えば、次のように指定できる。
-c -5—— 各行の最初の文字から5文字目までを取得する-c 7-9—— 各行の7〜9文字目を取得する
$ find . -type f | cut -c 7-9
ME.
n/s
n/s
dat
dat
複数の位置を指定したい場合は、カンマ(,)で位置指定を区切る。
例えば、下記のような指定のしかたが可能だ。
-c 12,15-—— 各行の12文字目と15文字目以降を取得する-c -3,5-8,10-—— 各行の4文字目と9文字目以外すべてを取得する
$ find . -type f | cut -c 12,15-
t
ar_a/speech_0001.wav
ar_b/speech_0002.wav
npeaker_a/speech_1001.wav
npeaker_b/speech_1002.wav
cut -c の指定のしかたを図で表すと、次のようになる。

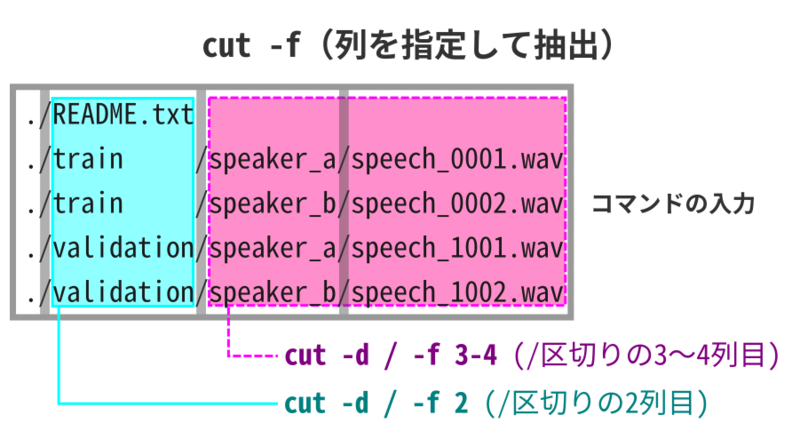
列を指定して抽出する
-f オプションを使うと、CSVフォーマットのように特定の文字で列を区切ったテキストから、指定した列の値を抽出できる。
区切り文字は -d オプションを使って指定できる。
先ほどと同様に、find コマンドの出力をフィルタする例を使って考えよう。
find の出力はファイルパスだ。
パスはスラッシュ(/)を区切り文字としているから、-d / とすれば、各ファイルパスを / で区切った列として扱えるようになる。
まずは、cut -d / -f 1 で最初の列を抽出してみよう。
$ find . -type f | cut -d / -f 1
.
.
.
.
.
全部 . になってしまった。
これは、find が出力した各行の先頭に ./ がついているからだ。
2番目の列を抽出すると(-f 2)、もっと意味のあるデータが得られる。
$ find . -type f | cut -d / -f 2
README.txt
train
train
validation
validation
各ファイルパスの2列目の値、つまりカレントディレクトリ直下のファイル名(ディレクトリ名)が得られた。
-c オプションと同様に、-f オプションでもコンマ(,)による複数列の指定や、ハイフン(-)を使った範囲指定ができる。
例えば、3列目と4列目の値だけを抽出したいときは、-f 3,4 か -f 3-4 と指定すればよい。
$ find . -type f | cut -d / -f 3-4
speaker_a/speech_0001.wav
speaker_b/speech_0002.wav
speaker_a/speech_1001.wav
speaker_b/speech_1002.wav
ちなみに、-d オプションを指定しないで -f オプションだけを指定した場合は、タブ記号(キーボードの Tab キーを押すと入力される空白文字)が区切り文字となる。
例題の解答
これで、前回の記事で示した例題を解くために必要な3つの要素 —— パイプ機能、tr コマンド、cut コマンド —— が揃った。
復習も兼ねて、前回の例題を再掲しよう。
❓ 課題
次に示すディレクトリ構造をもつデータセットがあるとしよう。
/home/me/dataset |-train/ | |-speaker_a/ | | |-speech_0001.wav | | |-speech_0002.wav | | ... | |-speaker_b/ | |-speaker_c/ | | ... | `-speaker_z/ `-validation/ |-speaker_a/ | |-speech_1001.wav | |-speech_1002.wav | ... |-speaker_b/ |-speaker_c/ | ... `-speaker_z/このデータセットの構成を、他のプログラム(Excel など)を使って分析したい。
そこで、データセット内に含まれるすべての
wavファイルのパスを、次のように 「trainまたはvalidation」、「話者」、「ファイル名」の3列をもつ CSV 形式で出力したい。 どうすればいいだろうか?train,speaker_a,speech_0001.wav train,speaker_a,speech_0002.wav ... validation,speaker_a,speech_1001.wav validation,speaker_a,speech_1002.wav ...
前回の記事では、次のように find と tr をパイプでつなぐことで、必要なCSVデータに近い出力が得られる、ということを学んだ。
$ cd /home/me/dataset
$ find . -name '*.wav' | tr / ,
.,train,speaker_a,speech_0001.wav
.,train,speaker_a,speech_0002.wav
...
.,validation,speaker_a,speech_1001.wav
.,validation,speaker_a,speech_1002.wav
...
各行の先頭に ., という余分な文字がくっついているが、cut コマンドを使えばこれを除去できる。
tr の出力をカンマ区切りのテキストと見なして、2列目以降の値だけを抽出すれば、課題で提示されたフォーマットどおりの出力が得られそうだ。
実際に、tr の後ろに cut をつなげてみよう。
カンマ区切りのテキストから2列目以降を抽出するコマンドは cut -d , -f 2- だ。
$ find . -name '*.wav' | tr / , | cut -d , -f 2-
train,speaker_a,speech_0001.wav
train,speaker_a,speech_0002.wav
...
validation,speaker_a,speech_1001.wav
validation,speaker_a,speech_1002.wav
...
フォーマットどおりの出力ができた。
出力リダイレクト を使って出力をファイルに保存すれば、Excel などのアプリで結果を集計・分析できる。
dataset.csv というファイル名で保存しておこう。
$ find . -name '*.wav' | tr / , | cut -d , -f 2- > dataset.csv
ちょっと長いコマンドだが、要素ごとに見ていくと次のようになる。
find—— カレントディレクトリ以下の、拡張子が.wavのファイルを検索するtr—— ファイルパスの/を,に置換するcut—— カンマ区切りの2列目以降を抽出する> dataset.csv——cutコマンドの出力をdataset.csvに保存する
まとめ
前回と今回の記事では、「ファイルパスをCSVに変換し、ファイルに保存する」という作業を題材として、find、tr、cut という3つのコマンドを組み合わせたパイプラインを構築した。
今回は2つのフィルタコマンド ——tr コマンドと cut コマンド——を紹介したが、Linux にはこれ以外にもたくさんのフィルタコマンドが用意されている。
それぞれのフィルタがもつ機能は単純だが、必要な機能を選んでパイプで組み合わせれば、高度な処理ができるようになる。
こうした複雑な操作ができるのは、CLI ユーザの特権と言ってもいい。
ここまではテキストデータの操作を中心に見てきたが、連載の初回で触れたように、Linux コマンドラインを使えば画像や映像などのマルチメディアも操作できる。 次回以降は、Linux を使った画像処理の例をみていこう。
それでは、次回の記事もお楽しみに!
🎯 まとめ
cut: 入力されたデータの各行から、指定した位置または列にある文字を抽出するコマンド
cut -c 3: 各行の3文字目だけを抽出するcut -d / -f 3-4: 各行をスラッシュ (/) で区切り、3〜4列目を抽出するfind . -name '*.wav' | tr / , | cut -d , -f 2-: 次の処理をするコマンド
- カレントディレクトリ以下にある、拡張子が
.wavで終わるファイルを再帰的に検索する- 検索にヒットしたファイルパスに含まれる
/を、すべて,に置き換える- カンマ区切りの2列目以降を抽出する
❓ 練習課題
- 記事の本文で示した例題をもとに、「WAVファイルのファイル番号」だけを抽出するコマンドを作成してみよう。
$ cd /home/me/dataset $ find . -name '*.wav' ./train/speaker_a/speech_0001.wav ./train/speaker_a/speech_0002.wav ... ./validation/speaker_a/speech_1001.wav ./validation/speaker_a/speech_1002.wav ... $ (下記の出力をもつコマンドを作成する) 0001 0002 ... 1001 1002